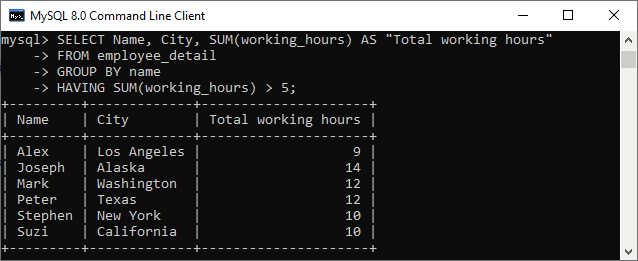
實作測驗 ~ 正規化 + SELECT
有如下表單,你應該如何進行正規化呢? 學號 學生姓名 學生電話 課程代號 課程名稱 年級 老師姓名/電話 老師代號 科系代號 科系名稱 成績 101001 張大頭 0910111222 0922111000 A001 資料庫 三年級 王老師 0933111333 001 001 資管系 80 A002 網路概論 林老師 0955111222 002 003 資工系 50 101002 劉三哥 0912333222 0922111333 A003 程式設計 三年級 孫老師 0912000333 003 001 資管系 85 A002 網路概論 林老師 0955111222 002 003 資工系 76 我們正規化後,資料結構如下~ studnt 學生資料表 ( studno , studname, deptid) teacher 老師資料表 ( teano , teaname, deptid) department 科系資料表 ( deptid , deptname) telephone 電話資料表 ( ownerno, tel ) cou…